생성형 AI, 이제는 성능 싸움이다! LLM(거대언어모델)의 모든 것

오픈AI의 대화형 인공지능 서비스 챗GPT에 대한 관심은 여전히 뜨겁습니다. 어렵고 복잡한 질문에도 단시간에 답변을 내놓는 것은 물론, 소설 창작이나 코딩도 가능한 만큼 인간을 대체할 수 있다는 우려 때문인데요. 하지만 “세종대왕의 맥북 던짐 사건에 대해 알려줘”와 같은 질문에도 내용을 지어서 긴 답변을 내어놓는 등 다소 황당한 모습을 보이기도 하죠. 이에 KAIST의 이경상 교수는 챗GPT를 뇌가 아닌 ‘혀’라고 정의했습니다.
하지만 이와 같은 대화형 인공지능 서비스들을 효과적으로 학습할 수 있는 언어 모델이 있다면 어떨까요? 실제 인간과 대화하는 것 같은 착각을 주는 AI챗봇이 등장할 수도 있지 않을까요? AI 개발의 최종 목표인 ‘인간과 동일한 수준’의 진화에 도전하는 거대 언어 모델, LLM(Large Language Model)을 탐구해 봅니다.
👉 관련 콘텐츠 보기 [인간만큼 똑똑한 인공지능의 시대? AI를 넘어 AGI의 단계로]
https://news.lginnotek.com/1285

생성형 AI를 발전시키는 LLM란 무엇일까?
LLM은 수많은 파라미터*를 보유한 인공 신경망으로 구성되는 언어 모델입니다. 언어 모델(LM)을 더욱 확장한 개념으로, 인간의 언어를 이해하고 생성하도록 훈련된 인공지능을 통틀어 LLM이라고 합니다. LLM은 수많은 양의 텍스트를 통해 훈련을 거듭한 뒤 맥락을 파악하여 적절한 답을 만들어내는데요. 한 문장이 주어졌을 경우, 한 단어가 끝나고 다음 단어를 예측할 때 단어들 사이의 유사성이나 문맥 형성 등을 파악하여 더욱 정확한 의미를 생성하죠.
챗GPT를 비롯한 여러 가지 생성형 AI들이 공개되면서 다른 IT기업들도 차세대 모델을 준비하고 있다고 하는데요. 이 생성형 AI가 제 역할을 하도록 만드는 것이 바로 LLM입니다.
*파라미터 : Parameter. 사용자가 원하는 방식으로 자료가 처리되도록 하기 위해 명령어를 입력할 때 추가하거나 변경하는 수치 정보.

LLM을 훈련시키는 파라미터는 매개변수라고도 하는데요. 사람의 뇌에서 사고 과정에 관여하는 시냅스와 같은 역할을 합니다. 쉽게 말하자면 뇌의 기능을 하는 것이죠. 파라미터의 개수가 많아질수록 더욱 고도화된 훈련이 가능해지는데요. 생성형 AI를 개발하는 기업에서 더 많은 수의 매개변수를 내세우는 것도 바로 이 이유 때문입니다.
하지만 파라미터의 개수가 많다고 해서 무조건적으로 성능이 좋다고는 할 수 없죠. 토큰(token)과 파인튜닝(fine-tuning) 등의 요소도 LLM을 학습시키는 데 필요합니다. 토큰은 LLM이 인식하는 문자 데이터 단위를 말해요. 컴퓨터가 입력값을 쉽게 이해하도록 텍스트를 쪼개 놓은 단위라고 볼 수 있습니다. 역시 토큰의 수만큼 학습량도 많아지겠죠. 파인튜닝은 LLM을 미세하게 조정하는 과정이에요. 학습한 데이터를 그대로 따라가게 되면 현실적인 답과는 거리가 멀거나 활용하기 어려운 답변이 나올 수도 있기 때문에 쓰임새에 맞게 조정하는 작업 또한 반드시 필요합니다. 선정성이나 폭력성으로 답변에 노출되어선 안 되는 부적절한 단어들을 필터링하거나, 편향된 답변을 걸러내는 후처리 작업도 파인튜닝에 속합니다.
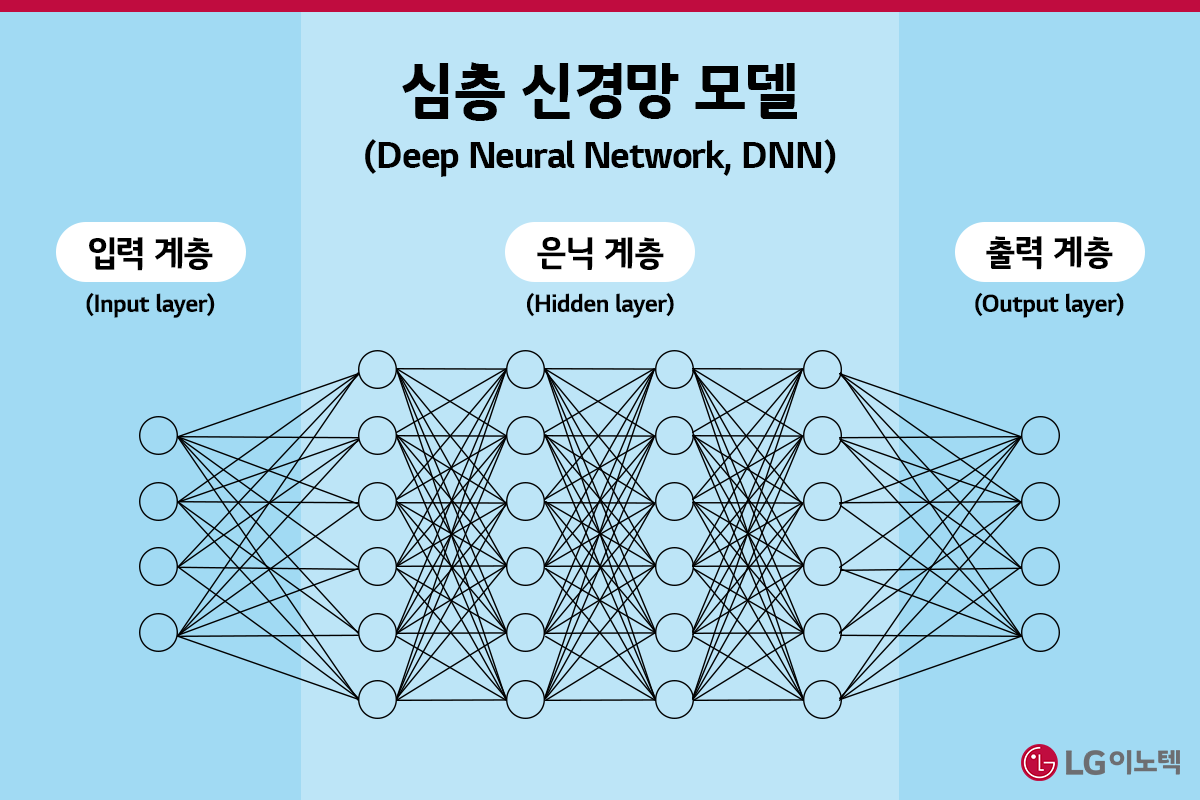
LLM은 입력층과 출력층 사이에 다중의 은닉 계층을 포함하는 심층 신경망 모델(Deep Neural Network, DNN)입니다. 사람의 뇌 신경망은 뉴런이라고 불리는 신경세포가 신호를 전달하는 과정을 거치는데요. 이를 모방한 것이 바로 인공 신경망(ANN)입니다. 수학적으로 구현한 인공 뉴런이 학습을 통해 문제 해결 능력을 갖게 하는 데 목적을 두고 있죠. 그리고 인공 신경망의 레이어를 많이 쌓아 발전된 알고리즘으로 구현해낸 것이 심층 신경망입니다. 1단계 인풋으로 2단계 아웃풋을, 2단계를 기반으로 3단계 아웃풋을 내는 식으로 학습을 하는 형태죠. 활용하는 레이어 수가 많을수록 더욱 높은 정확도를 기록하게 됩니다.
심층 신경망 알고리즘을 통해 사람보다 더 안정적으로 운전하는 자율주행차를 개발할 수 있는 것은 물론, 사람처럼 글을 쓰고 작곡을 하거나 그림ㆍ사진을 만드는 등의 창작도 할 수 있는데요. 이미 AI를 활용한 소설과 그림, 디자인까지 등장하고 있는 추세입니다. 기계가 인간을 대체할지도 모른다는 걱정이 점점 현실로 다가오고 있는 것이죠.
👉 관련 콘텐츠 보기 [AI가 그림, 음악, 문학 작품을 만드는 시대가 온다? AI 예술의 세계]
https://news.lginnotek.com/1194

LLM, 어떻게 활용할 수 있을까?
LLM은 데이터를 다루는 산업 전반에 활용이 가능한 기술입니다. 특히 서비스를 즉각적으로 이용할 수 있도록 보조하는 역할을 하는데요. 챗봇이나 AI비서 등으로 고객 서비스의 퀄리티를 높일 수 있고요. 직접적인 응답을 제공하는 검색 엔진도 구현할 수 있습니다. 소프트웨어의 코드를 작성하는 데 도움을 받을 수도 있고, 수익 결산을 요약하면서 이상 징후를 감지하거나 사기 가능성을 분석하여 고객의 손실을 최소화할 수도 있습니다. 고객만족도와 같은 데이터를 세부적으로 분류하여 만족도 높은 서비스를 기획하는 데 도움을 받을 수도 있겠죠.
자율주행차에도 LLM이 적용된다면 목적지까지 안전한 주행이 가능해질 거예요. 천재지변이나 교통사고 등의 돌발상황에서 인간의 명령을 빠르게 이해하고 수행해야 하기 때문이죠. 완전한 형태의 LLM이 개발된다면, 완전자율주행 단계의 자율주행차를 기대해봐도 되지 않을까요?
👉 관련 콘텐츠 보기 [완전 자율주행 시대를 앞당기는 LG이노텍 5G-V2X]
https://news.lginnotek.com/1341

LLM, 어디까지 왔을까?
글로벌 IT기업뿐만 아니라 국내 기업에서도 LLM의 개발을 위해 대규모 투자와 연구를 진행하고 있습니다. 국내 기업이 요긴하게 활용할 수 있으려면 한국어 데이터를 대량으로 갖고 있어야 하는데요. 45조 개의 영어 데이터 토큰을 학습한 GPT-3에는 한국어 데이터의 학습량이 전체 비중에서 0.01697%(1억 개)에 불과하여 국내 기업이 활용하기 어렵기 때문입니다. 이에 한국어 데이터를 대량으로 확보하는 움직임이 일고 있습니다. 방대한 한국어 데이터를 다룰 수 있는 국내 생성형 AI 또한 개발 중에 있어 많은 이들의 기대를 모으고 있어요. LG AI연구원의 초거대 AI모델 엑사원(EXAONE)도 한국어 데이터를 대량 학습한 생성형 AI 서비스입니다.
일각에서는 LLM을 직접 구축하는 데 방대한 비용이 드는 만큼, 글로벌 빅테크 모델을 참고하여 전문 AI모델을 만들거나 API를 활용하여 특정 산업분야의 서비스를 만드는 것이 더 효율적이라는 의견도 제기되고 있어요. 파라미터의 수를 줄여 더 가볍게, 꼭 필요한 부분에만 특화한 sLLM(small LLM, 경량 거대언어모델)을 활용하는 방법도 있고요.

LLM 서비스의 한계점으로 할루시네이션*과 데이터 유출 문제가 지적되곤 합니다. 하지만 오픈소스 모델의 기능 향상에 따라 개선될 가능성이 점차 높아지고 있죠. 한국어 데이터를 학습한 LLM이 상용화된다면 다양한 서비스를 좀 더 편리하고 실감나게 체험할 수도 있을 거예요.
*할루시네이션 : Hallucination. 환각, 환영, 환청을 뜻하는 영어단어로, 주어진 데이터나 맥락에 근거하지 않은 정보나 허위 정보를 생성하는 문제
1966년에 만들어진 일라이자(ELIZA)는 정신과 환자 상담용으로 사용되었던 AI 채팅 프로그램이었습니다. 간단한 알고리즘이었지만, 상담을 진행한 환자들은 일라이자를 사람처럼 여겼습니다. 이처럼 알고리즘을 따르는 기계ㆍ로봇ㆍAI를 인간처럼 여기는 현상을 일라이자 효과라고 부르기 시작했는데요. 기술의 고도화로 더욱 세밀해진 LLM으로 일라이자 효과를 겪는 이들이 지금보다 더 늘어날 수도 있겠다는 생각이 듭니다. 어쩌면 실제 인간과 혼동하는 현상을 ‘LLM 효과’라고 정의하는 날이 올 수도 있겠죠. 물론 그때는 일라이자와는 비교할 수 없을 만큼 정교한 구조로 인간을 24시간 돕고 있지 않을까요? 친구, 조력자, 해결사 등 여러 가지 역할을 수행할 LLM 모델을 기대해 봅니다.
👉 관련 콘텐츠 보기 [건강 돌봄, 사고 예방, 인명 구조까지! 사람 살리는 착한 IT기술]
https://news.lginnotek.com/1292
